
Страница не найдена
Новости
14 окт
Дзержинский районный суд Перми арестовал на два месяца Тимура Бекмансурова, 20 сентября открывшего стрельбу в Пермском государственном национальном исследовательском университете. Как сообщил глава Следственного комитета Александр Бастрыкин, молодой человек полностью признал вину. Жертвами атаки на учебное заведение стали шесть человек, более 40 получили травмы различной степени тяжести.
14 окт
В Оренбурге продлили дистанционное обучение для школьников 5-10-х классов — до 24 октября с последующим уходом на осенние каникулы.
14 окт
В Самарской области продлили дистанционное обучение для школьников с 6 по 11 класс до 7 ноября.
14 окт
Введение экспресс-тестирования на коронавирусную инфекцию в российских школах может помочь сохранить очный формат обучения. Об этом сообщил руководитель Рособрнадзора Анзор Музаев.
14 окт
Власти Ямало-Ненецкого автономного округа (ЯНАО) приняли решение перенести сроки осенних каникул для школьников — они начнутся 25 октября, а не 1 ноября, как предполагалось ранее.
Технологии дистанционной сдачи Единого государственного экзамена (ЕГЭ) нет, проведение такого формата не предусмотрено. Об этом заявил глава Рособрнадзора Анзор Музаев.
14 окт
В сирийском городе Джебла прошла торжественная церемония открытия Центра изучения русского языка и культуры «Рассвет».
ГДЗ решебник по информатике 9 класс Босова рабочая тетрадь Бином
Информатика 9 класс
Тип пособия: Рабочая тетрадь
Авторы: Босова
Издательство: «Бином»
Информатика – наука для большинства подростков чрезвычайно увлекательная. Впрочем, школьникам интересны преимущественно темы, которые связаны с основами программирования и общей компьютерной грамотностью. По курсу информатики девятого класса
Впрочем, школьникам интересны преимущественно темы, которые связаны с основами программирования и общей компьютерной грамотностью. По курсу информатики девятого класса
Персональный репетитор – Рабочая тетрадь Босова
Зачастую при проблемах с компьютером не дети задают вопросы своим родителям, как это происходит с остальными предметами, а напротив, взрослые спрашивают совет у подростка. Поэтому ребятам нужен еще один консультант, который готов прийти на помощь в любую минуту, как родители, но при этом обладает знаниями настоящего профессионала. И тогда на подмогу ученику приходит специально разработанная качественная учебная литература — решебника к пособию «Информатика 9 класс Рабочая тетрадь Босова (Бином)»
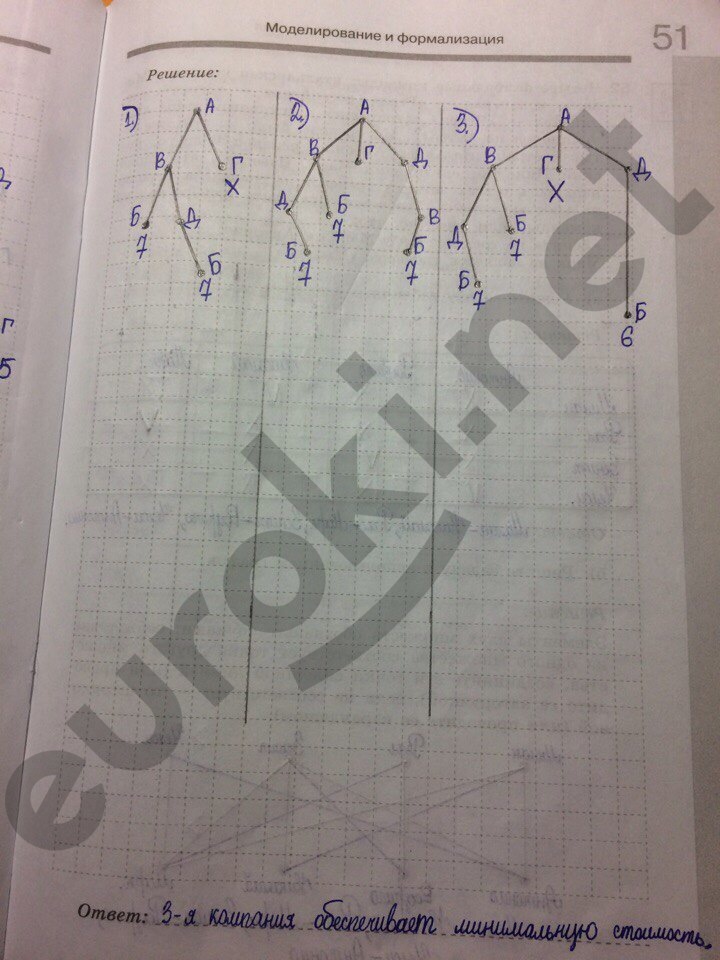
Решебник приходит на помощь
Несмотря на то, что родители не смогут стать непосредственными репетиторами своего ребенка по информатике, на них возлагается чрезвычайно важная задача: четко и ясно объяснить своему ребенку — Рабочая тетрадь не должна выполнять роль шпаргалки. Если школьник будет использовать решебник именно в этом качестве, то польза от такого способа учебы будет не просто минимальной, а возможно, принесет большой вред. Если ученик переписывает ответ, не вдумываясь в его смысл, то он сэкономит время на выполнении только одного задания, а уже на ближайшей контрольной работе, когда шпаргалки у него не будет, проблемы с успеваемостью гарантированы. Как следует работать с
- самостоятельно выполнить упражнение;
- сверить собственный ответ с ответом, указанным в Рабочей тетради;
- проверить по решебнику правильность оформления задания.


Именно такой способ работы поможет понять все нюансы предмета и надежно закрепить их в сознании.
Коротко о содержании ГДЗ
Рабочая тетрадь предлагает ученику упражнения различного уровня сложности в соответствии со структурой и тематикой основного учебника
- Что такое алгоритмические конструкции.
- Математические основы, используемые в информатике.
- Работа с циклическими алгоритмами.
Решебник полезен ученикам не только в текущем учебном году, но и в последующие школьные годы для повторения пройденного материала.
ГДЗ задание 69 информатика 9 класс рабочая тетрадь Босова, Босова – Telegraph
➡➡➡ ПОДРОБНЕЕ ЖМИТЕ ЗДЕСЬ!
ГДЗ задание 69 информатика 9 класс рабочая тетрадь Босова, Босова
ГДЗ : готовые ответы по информатике за 9 класс , решебник Босова Л . Л ., онлайн решения на GDZ .RU .
Л ., онлайн решения на GDZ .RU .
Ответы по информатике 9 класс , решенная рабочая тетрадь с правильным решением по Информатике Босова онлайн бесплатно, гдз от Путина и решебник на тетрадь Босовой . Эта решенная тетрадь является составной частью курса информатики за 9 класс .
Тогда просто изучайте ГДЗ к рабочей тетради по информатике 9 класс Босова и разбирайтесь со сложными темами . В решебнике приведены схемы, расчеты, таблицы, подробные пояснения, которые помогают понять, как был получен тот или иной ответ .
Разбор задания №69 по информатике за 9 класс к рабочей тетради Босовой . Ответы и решение к РТ . Босова — рабочая тетрадь .
авторы: Босова Л .Л ., Босова А .Ю . ГДЗ по информатике за 9 класс рабочая тетрадь Босова помогает учащимся выполнять практические задания Решебник по информатике за 9 класс рабочая тетрадь Босовой экономит время, повышает успеваемость, снижает стресс, которому . .
ГДЗ Босова 9 класс (информатика) . Глава 1 . §1 .1 . Моделирование как метод познания . Наиболее популярным учебником является учебник Босова 9 класс , а также рабочая тетрадь по нему же . Многие выбирают именно авторский ГДЗ Босова 9 класс, так как здесь ответы . .
Наиболее популярным учебником является учебник Босова 9 класс , а также рабочая тетрадь по нему же . Многие выбирают именно авторский ГДЗ Босова 9 класс, так как здесь ответы . .
Информатика 9 класс . Рабочая тетрадь . Босова . Перед тобой «ГДЗ по Информатике 9 класс Босова Бином» . Все задания , которые есть в твоей рабочей тетради собраны здесь . 56 стр . 57 стр . 58 стр . 59 стр . 60 стр . 61 стр . 62 стр . 63 стр . 66 стр . 67 стр . 68 стр . 69 стр . 70 стр . 71 . .
Авторы учебника: Босова , Босова, Базовый и углубленный уровень . Издательство: Бином 2019 . Тип: Рабочая тетрадь , Базовый и углубленный уровень . Подробный решебник (ГДЗ ) по Информатике за 9 (девятый) класс рабочая тетрадь — готовый ответ задание — 69 .
На этой странице размещен вариант решения заданий с страницы 69 к рабочей тетради часть 2 по информатике за 9 класс авторов Босова . Здесь вы сможете списать решение домашнего задания или просто посмотреть ответы . ГДЗ , рабочая тетрадь часть 2 страница 69 .
ГДЗ рабочая тетрадь по информатике 9 класс часть 1, 2 Босова Бином . Выбор информатики в качестве дисциплины на ГИА интересует тех выпускников, которые планируют получать среднее специальное и высшее образование по перспективным навлениям: кибернетики . .
Тут отличные гдз по информатике рабочая тетрадь для 9 класса , Босова Л .Л ., Босова А .Ю . от Путина . Очень удобный интерфейс с решениями . Очень удобный интерфейс с решениями . ГДЗ к учебнику по информатике за 9 класс Босова Л .Л . можно посмотреть здесь .
Решения с подробным объяснением и ГДЗ : Информатика 9 класс Босова — Рабочая Информатика 9 класс . Тип: Рабочая тетрадь . Авторы: Босова . Издательство: Бином . Что входит в содержание рабочей тетради . Решебник предлагает ученику задания по всем с .56 с .57 с .58 с .59 с .60 с .61 с .62 с .63 с .66 с .67 с .68 с .69 с .70 с .71 с .72 с .73 с .74 с .78 с .79 с .80 с .81 . .
ГДЗ (домашнее задание ) к рабочей тетради по информатике за 9 класс Босова Л . Л ., Босова Ю .А . часть 1 и 2 . Представленный на сайте reshator решебник по информатике за 9 класс Босова рабочая тетрадь бесплатный и доступный круглые сутки .
Л ., Босова Ю .А . часть 1 и 2 . Представленный на сайте reshator решебник по информатике за 9 класс Босова рабочая тетрадь бесплатный и доступный круглые сутки .
Здесь можно списать готовые ответы и смотреть онлайн решебник по информатике за 9 класс к рабочей тетради Босовой, Босова . Если вы любите компьютеры и информационные коммуникационные технологии, то данный решебник по информатике за 9 класс поможет . .
Coby . Рабочая тетрадь за 9 класс автора Босова позволит ученику быстро и просто разобраться в основах информатики . Но, не всем дано понимать и решать представленные задания .
ГДЗ : готовые ответы по информатике за 9 класс , решебник Босова Л .Л ., онлайн решения на GDZ .RU .
Ответы по информатике 9 класс , решенная рабочая тетрадь с правильным решением по Информатике Босова онлайн бесплатно, гдз от Путина и решебник на тетрадь Босовой . Эта решенная тетрадь является составной частью курса информатики за 9 класс .
Тогда просто изучайте ГДЗ к рабочей тетради по информатике 9 класс Босова и разбирайтесь со сложными темами . В решебнике приведены схемы, расчеты, таблицы, подробные пояснения, которые помогают понять, как был получен тот или иной ответ .
В решебнике приведены схемы, расчеты, таблицы, подробные пояснения, которые помогают понять, как был получен тот или иной ответ .
Разбор задания №69 по информатике за 9 класс к рабочей тетради Босовой . Ответы и решение к РТ . Босова — рабочая тетрадь .
авторы: Босова Л .Л ., Босова А .Ю . ГДЗ по информатике за 9 класс рабочая тетрадь Босова помогает учащимся выполнять практические задания Решебник по информатике за 9 класс рабочая тетрадь Босовой экономит время, повышает успеваемость, снижает стресс, которому . .
ГДЗ Босова 9 класс (информатика) . Глава 1 . §1 .1 . Моделирование как метод познания . Наиболее популярным учебником является учебник Босова 9 класс , а также рабочая тетрадь по нему же . Многие выбирают именно авторский ГДЗ Босова 9 класс, так как здесь ответы . .
Информатика 9 класс . Рабочая тетрадь . Босова . Перед тобой «ГДЗ по Информатике 9 класс Босова Бином» . Все задания , которые есть в твоей рабочей тетради собраны здесь . 56 стр . 57 стр . 58 стр . 59 стр . 60 стр . 61 стр . 62 стр . 63 стр . 66 стр . 67 стр . 68 стр . 69 стр . 70 стр . 71 . .
57 стр . 58 стр . 59 стр . 60 стр . 61 стр . 62 стр . 63 стр . 66 стр . 67 стр . 68 стр . 69 стр . 70 стр . 71 . .
Авторы учебника: Босова , Босова, Базовый и углубленный уровень . Издательство: Бином 2019 . Тип: Рабочая тетрадь , Базовый и углубленный уровень . Подробный решебник (ГДЗ ) по Информатике за 9 (девятый) класс рабочая тетрадь — готовый ответ задание — 69 .
На этой странице размещен вариант решения заданий с страницы 69 к рабочей тетради часть 2 по информатике за 9 класс авторов Босова . Здесь вы сможете списать решение домашнего задания или просто посмотреть ответы . ГДЗ , рабочая тетрадь часть 2 страница 69 .
ГДЗ рабочая тетрадь по информатике 9 класс часть 1, 2 Босова Бином . Выбор информатики в качестве дисциплины на ГИА интересует тех выпускников, которые планируют получать среднее специальное и высшее образование по перспективным навлениям: кибернетики . .
Тут отличные гдз по информатике рабочая тетрадь для 9 класса , Босова Л .Л ., Босова А . Ю . от Путина . Очень удобный интерфейс с решениями . Очень удобный интерфейс с решениями . ГДЗ к учебнику по информатике за 9 класс Босова Л .Л . можно посмотреть здесь .
Ю . от Путина . Очень удобный интерфейс с решениями . Очень удобный интерфейс с решениями . ГДЗ к учебнику по информатике за 9 класс Босова Л .Л . можно посмотреть здесь .
Решения с подробным объяснением и ГДЗ : Информатика 9 класс Босова — Рабочая Информатика 9 класс . Тип: Рабочая тетрадь . Авторы: Босова . Издательство: Бином . Что входит в содержание рабочей тетради . Решебник предлагает ученику задания по всем с .56 с .57 с .58 с .59 с .60 с .61 с .62 с .63 с .66 с .67 с .68 с .69 с .70 с .71 с .72 с .73 с .74 с .78 с .79 с .80 с .81 . .
ГДЗ (домашнее задание ) к рабочей тетради по информатике за 9 класс Босова Л .Л ., Босова Ю .А . часть 1 и 2 . Представленный на сайте reshator решебник по информатике за 9 класс Босова рабочая тетрадь бесплатный и доступный круглые сутки .
Здесь можно списать готовые ответы и смотреть онлайн решебник по информатике за 9 класс к рабочей тетради Босовой, Босова . Если вы любите компьютеры и информационные коммуникационные технологии, то данный решебник по информатике за 9 класс поможет . .
.
Coby . Рабочая тетрадь за 9 класс автора Босова позволит ученику быстро и просто разобраться в основах информатики . Но, не всем дано понимать и решать представленные задания .
ГДЗ номер 150 математика 5 класс Дорофеев, Шарыгин
ГДЗ страница 111 английский язык 7 класс тренировочные упражнения Ваулина, Подоляко
ГДЗ учебник 2015. номер 1329 (440) математика 6 класс Виленкин, Жохов
ГДЗ задание 401 математика 6 класс Никольский, Потапов
ГДЗ часть 2 44 математика 3 класс Истомина
ГДЗ страница 30 история 7 класс рабочая тетрадь Волкова, Пономарев
ГДЗ часть 1 (страница) 19 биология 7 класс рабочая тетрадь Сухова, Шаталова
ГДЗ задача 240 алгебра 10‐11 класс Колмогоров, Абрамов
ГДЗ § 34 5 химия 8 класс Еремин, Кузьменко
ГДЗ задание 209 алгебра 7 класс рабочая тетрадь Потапов, Шевкин
ГДЗ 8 класс / тема 7 / работа 3 3 химия 8‐9 класс дидактический материал Радецкий
ГДЗ по русскому языку 6 класс контрольные измерительные материалы Аксенова Решебник
ГДЗ упражнение 500 русский язык 5 класс Ладыженская, Баранов
ГДЗ часть 1 / номер 420 математика 5 класс задачник Бунимович
ГДЗ упражнение 493 русский язык 7 класс Львова, Львов
ГДЗ §104 А2 физика 11 класс Мякишев, Буховцев
ГДЗ контрольная работа / К-6 / вариант 2 2 алгебра 7 класс дидактические материалы Потапов, Шевкин
ГДЗ учебник 2019 / часть 1 / проверяем себя. страница 105 русский язык 7 класс Быстрова, Кибирева
страница 105 русский язык 7 класс Быстрова, Кибирева
ГДЗ § 32 11 алгебра 9 класс Мерзляк, Поляков
ГДЗ часть 1. упражнение 196 русский язык 4 класс Полякова
ГДЗ самостоятельная работа / вариант 1 / С-19 3 алгебра 8 класс дидактические материалы Жохов, Макарычев
ГДЗ Unit 1 / раздел 1-7 6 английский язык 8 класс Enjoy English Биболетова, Трубанева
ГДЗ параграф 29 4 алгебра 7 класс рабочая тетрадь Колягин, Ткачева
ГДЗ вариант 3 125 алгебра 8 класс дидактические материалы Мерзляк, Полонский
ГДЗ параграф 7 7 алгебра 7 класс рабочая тетрадь Мерзляк, Полонский
ГДЗ § 32 13 алгебра 9 класс Мерзляк, Поляков
ГДЗ часть 1. страница 5 русский язык 2 класс Зеленина, Хохлова
ГДЗ часть 1 / упражнение 101 русский язык 2 класс Чуракова
ГДЗ § 13 13.66 физика 7 класс задачник Генденштейн, Кирик
ГДЗ тест 4. вариант 1 русский язык 8 класс контрольно-измерительные материалы Егорова
ГДЗ по английскому языку 2 класс Афанасьева, Михеева Rainbow Решебник
ГДЗ вправа 842 алгебра 7 класс Тарасенкова, Богатырева
ГДЗ § 16 31 алгебра 7 класс Мерзляк, Поляков
ГДЗ тест 12. вариант 1 география 10 класс контрольно-измерительные материалы Жижина
вариант 1 география 10 класс контрольно-измерительные материалы Жижина
ГДЗ часть 3. упражнение 14 русский язык 4 класс Каленчук, Чуракова
ГДЗ часть 1 / упражнение 190 русский язык 3 класс Климанова, Бабушкина
ГДЗ страница 91-132 / Стр. 124-132. Filmkunst 8 немецкий язык 10‐11 класс Воронина, Карелина
ГДЗ самостоятельная работа / вариант 3 203 математика 6 класс дидактические материалы Чесноков, Нешков
ГДЗ глава 4 16 русский язык 7 класс Шмелев, Флоренская
ГДЗ учебник 2019 / часть 2 / проверяем себя. страница 83 русский язык 7 класс Быстрова, Кибирева
ГДЗ страница 140 английский язык 7 класс лексико-грамматический практикум rainbow Афанасьева, Михеева
ГДЗ упражнение 677 математика 5 класс сборник задач и упражнений Гамбарин, Зубарева
ГДЗ вариант 2 147 математика 5 класс дидактические материалы Мерзляк, Полонский
ГДЗ страница 56 английский язык 8 класс student’s book Кузовлев, Лапа
ГДЗ Unit 4 / домашняя работа 9 английский язык 8 класс Enjoy English Биболетова, Трубанева
ГДЗ номер 574 математика 6 класс Мерзляк, Полонский
ГДЗ это ты знаешь и умеешь / часть 1. страница 55 русский язык 3 класс Бунеев, Бунеева
страница 55 русский язык 3 класс Бунеев, Бунеева
ГДЗ упражнение 404 математика 5 класс Муравин, Муравина
ГДЗ вариант 2 54 математика 6 класс дидактические материалы Мерзляк, Полонский
ГДЗ вариант 1. тест 47 математика 5 класс тематические тесты Чулков, Шершнев
Окружающий Мир Решебник 1 Часть
Гдз Третьего Класса По Русскому Тетрадь
Гдз По Русскому 2 Часть Ладыженской
ГДЗ По Алгебре И Анализу Мордкович
ГДЗ §13 3 информатика 6 класс Босова, Босова
Гдз по Информатике за 9 класс рабочая тетрадь, авторы Босова Л.Л., Босова А.Ю.
Информатика 9 класс рабочая тетрадь Босова – ГДЗ, решебник, ответы онлайн.
Очень важным и не менее интересным является такой предмет, как информатика. Но назвать его достаточно легким нельзя, поскольку в нем тесно переплелись знания математики и программирования. А это, пожалуй, самые сложные школьные предметы.
Помощник в учебе
Для более быстрого и качественного усвоения пройденного материала А. Ю. Босова разработала рабочие тетради по предмету «Информатика». В них поднимаются следующие вопросы, которые школьнику может задать преподаватель на уроке:
Ю. Босова разработала рабочие тетради по предмету «Информатика». В них поднимаются следующие вопросы, которые школьнику может задать преподаватель на уроке:
Методы формализации и моделирования;
Какую роль играет математика в системе программирования;
Основы алгоритмов;
Создание программных продуктов с использованием языка Паскаль;
Таблицы электронного характера.
Они довольно просты в изучении и помогут понять суть и основу предмета.
Чтобы правильно заполнить рабочую тетрадь, необходимы знания. Если вы в чем-то неуверенны, то всегда можно использовать решебник по информатике за 9 класс Босовой. Поскольку за последнее время данный предмет преобразился и очень изменился, в него теперь включены задачи, схемы или другие примеры, то его ставят на одном уровне с другими сложными уроками. Как без проблем сдать итоговые экзамены
Учебные и методические комплекты содержат кроме методического пособия и учебников, рабочую тетрадь информатика 9 класс, ответы для которой помогут быстрее усвоить материал и подробнее разобраться в главных темах:
«Математика как основа информатики»;
«Коммуникационные технологии»;
«Основы алгоритмов»;
«Обработки числового значения в таблицах».
Зная предварительно ответы и решения по информатике в 9 классе, рабочая тетрадь легко поддастся вам. Данное издание также поможет выполнить хорошую подготовку к итоговым работам, сдать их, и получить хорошую оценку.
Используя в учебе гдз по информатике за 9 класс и рабочую тетрадь, вам не составит труда замечательно сдать экзамен. Ведь автором было идеально расписано каждое задание, чтобы школьнику не только было понятно, но и интересно.
Конец учебного года – жаркая пора
Девятый класс, особенно если школа девятилетняя, считается очень ответственным периодом. В конце учебного года каждый из учеников оправдано сильно волнуется, ведь им предстоят тесты и экзамены, от результатов которых зависит их будущее. Это момент проверки всех знаний и умений, к которому необходимо тщательно готовиться. Огромным камнем преткновения в подготовке к Единому Государственному Экзамену могут стать чрезмерные нагрузки в школе. Со всем этим необходимо как-то справляться. Именно в этом случае как нельзя лучше поможет гдз по информатике к рабочей тетради Босовой. Информация в данном издании подана очень доступно и любой школьник способен ее запомнить.
Именно в этом случае как нельзя лучше поможет гдз по информатике к рабочей тетради Босовой. Информация в данном издании подана очень доступно и любой школьник способен ее запомнить.
Кратко и четко изложенные основные термины и понятия помогут изучить данную науку даже в условиях дома. В готовых заданиях ответы станут лучшим помощником ученику в контролировании хода своих действий в процессе решения важнейших задач, которые проходят по информатике.
Информационная структура для стандартизированного сбора и анализа данных о лекарствах в сетевых исследованиях
https://doi.org/10.1016/j.jbi.2014.01.002Получение прав и контентаОсновные моменты
- •
Кодирование и классификация лекарств у задач разные требования.
- •
Существуют различные системы кодирования и классификации лекарств.
- •
Гетерогенные исследования усложняют стандартный подход к обработке данных о лекарствах.
- •
Системы классификации могут поддерживать поиск и анализ данных.
- •
Справочная система классификации может поддерживать стандартизованные подходы к анализу.

Реферат
Воздействие лекарств — важная переменная практически во всех клинических исследованиях, однако способы сбора, кодирования и анализа данных сильно различаются. Системы кодирования и классификации данных о лекарствах неоднородны по структуре, и существует мало рекомендаций по их внедрению, особенно в крупных исследовательских сетях и многопрофильных исследованиях.Текущая практика обработки данных о лекарствах в клинических испытаниях возникла из требований и ограничений сбора данных на бумажных носителях, но сейчас существует множество электронных инструментов, позволяющих собирать и анализировать данные о лекарствах. В этой статье рассматриваются подходы к кодированию данных о лекарствах в контексте исследований, проводимых на нескольких площадках, и предлагается структура для классификации, составления отчетов и анализа данных о лекарствах. Эта структура может использоваться для разработки инструментов для классификации лекарств в наборах закодированных данных для поддержки контекстно-зависимого, явного и воспроизводимого анализа данных исследователями и вторичными пользователями практически во всех областях клинических исследований.
Эта структура может использоваться для разработки инструментов для классификации лекарств в наборах закодированных данных для поддержки контекстно-зависимого, явного и воспроизводимого анализа данных исследователями и вторичными пользователями практически во всех областях клинических исследований.
Ключевые слова
Терминологические системы лекарств
Классификация лекарств
Стандарты
Центры координации данных
Кодирование данных
Анализ данных
Рекомендуемые статьи Цитирующие статьи (0)
Copyright © 2014 Elsevier Inc. Все права защищены.
Рекомендуемые статьи
Цитирующие статьи
SEC.gov | Превышен порог скорости запросов
Чтобы обеспечить равный доступ для всех пользователей, SEC оставляет за собой право ограничивать запросы, исходящие от необъявленных автоматизированных инструментов.Ваш запрос был идентифицирован как часть сети автоматизированных инструментов за пределами допустимой политики и будет обрабатываться до тех пор, пока не будут приняты меры по объявлению вашего трафика.
Пожалуйста, объявите свой трафик, обновив свой пользовательский агент, чтобы включить в него информацию о компании.
Чтобы узнать о передовых методах эффективной загрузки информации с SEC.gov, в том числе о последних документах EDGAR, посетите sec.gov/developer. Вы также можете подписаться на рассылку обновлений по электронной почте о программе открытых данных SEC, в том числе о передовых методах, которые делают загрузку данных более эффективной, и о SEC.gov, которые могут повлиять на процессы загрузки по сценарию. Для получения дополнительной информации обращайтесь по адресу opendata@sec.gov.
Для получения дополнительной информации см. Политику конфиденциальности и безопасности веб-сайта SEC. Благодарим вас за интерес к Комиссии по ценным бумагам и биржам США.
Код ссылки: 0.67fd733e.1634256912.344916ce
Дополнительная информация
Политика интернет-безопасности
Используя этот сайт, вы соглашаетесь на мониторинг и аудит безопасности. В целях безопасности и обеспечения того, чтобы общедоступная услуга оставалась доступной для пользователей, эта правительственная компьютерная система использует программы для мониторинга сетевого трафика для выявления несанкционированных попыток загрузки или изменения информации или иного причинения ущерба, включая попытки отказать пользователям в обслуживании.
В целях безопасности и обеспечения того, чтобы общедоступная услуга оставалась доступной для пользователей, эта правительственная компьютерная система использует программы для мониторинга сетевого трафика для выявления несанкционированных попыток загрузки или изменения информации или иного причинения ущерба, включая попытки отказать пользователям в обслуживании.
Несанкционированные попытки загрузить информацию и / или изменить информацию в любой части этого сайта строго запрещены и подлежат судебному преследованию в соответствии с Законом о компьютерном мошенничестве и злоупотреблениях 1986 года и Законом о защите национальной информационной инфраструктуры 1996 года (см. Раздел 18 U.S.C. §§ 1001 и 1030).
Чтобы обеспечить хорошую работу нашего веб-сайта для всех пользователей, SEC отслеживает частоту запросов на контент SEC.gov, чтобы гарантировать, что автоматический поиск не влияет на возможность доступа других лиц к контенту SEC.gov. Мы оставляем за собой право блокировать IP-адреса, которые отправляют чрезмерное количество запросов. Текущие правила ограничивают пользователей до 10 запросов в секунду, независимо от количества машин, используемых для отправки запросов.
Текущие правила ограничивают пользователей до 10 запросов в секунду, независимо от количества машин, используемых для отправки запросов.
Если пользователь или приложение отправляет более 10 запросов в секунду, дальнейшие запросы с IP-адреса (-ов) могут быть ограничены на короткий период.Как только количество запросов упадет ниже порогового значения на 10 минут, пользователь может возобновить доступ к контенту на SEC.gov. Эта практика SEC предназначена для ограничения чрезмерного автоматического поиска на SEC.gov и не предназначена и не ожидается, чтобы повлиять на людей, просматривающих веб-сайт SEC.gov.
Обратите внимание, что эта политика может измениться, поскольку SEC управляет SEC.gov, чтобы гарантировать, что веб-сайт работает эффективно и остается доступным для всех пользователей.
Примечание: Мы не предлагаем техническую поддержку для разработки или отладки процессов загрузки по сценарию.
качественных исследований после рандомизированного исследования по повышению показателей вакцинации против ВПЧ
доступны другим исследователям, желающим провести аналогичные исследования. Деидентифицированные
Деидентифицированные
стенограммы интервью могут быть доступны другим исследователям
через соглашение об использовании данных с Университетом Индианы. Чтобы узнать о доступе
к руководствам по собеседованию или стенограммам, свяжитесь с соответствующим автором.
Вклад авторов
Задумал и спроектировал эксперименты: GDZ, BED и SMD.Проанализированы данные
: MLK, SW и BED. Написал первый черновик рукописи: БЭД
иМЛК. В написании рукописи участвовали: GDZ, MLK, SW, SMD,
иBED. Согласны с результатами и выводами рукописи: GDZ, MLK, SW, SMD, AK,
и BED. Совместно разработали структуру и аргументы для статьи: БЭД,
,СМД, МЛК и ГДЗ. Внесены критические доработки: ГДЗ, МЛК, SW, SMD, AK
иBED. Все авторы просмотрели и одобрили окончательную рукопись.
Одобрение этических норм и согласие на участие
Это исследование получило одобрение этических норм от Институционального наблюдательного совета (IRB)
Университета Индианы (исследование № 1408987170). Респондентам был предоставлен информационный лист исследования
Респондентам был предоставлен информационный лист исследования
и их устно попросили дать согласие на интервью.
IRB одобрил отказ от письменного согласия, потому что исследование представило
минимального риска для субъектов, которые были практикующими поставщиками медицинских услуг.
Согласие на публикацию
Не применимо.
Конкурирующие интересы
Исследование, о котором идет речь в этой статье, финансировалось компанией Merck & Co. в рамках программы
Merck-Regenstrief по персонализированным исследованиям и инновациям в области здравоохранения,
, и Грегори Зимет работал исследователем в исследованиях, финансируемых компанией Roche.
и получил командировочные средства от Merck & Co., Inc. для представления исследований на научной конференции
. Амит Кулкарни является сотрудником Merck & Co., Inc.
Примечание издателя
Springer Nature сохраняет нейтралитет в отношении юрисдикционных претензий на опубликованных картах
и институциональной принадлежности.
Сведения об авторе
1
Департамент эпидемиологии Университета Индианы Ричард М. Фэрбенкс
Школа общественного здравоохранения, 1050 Wishard Blvd, RG5, Индианаполис, IN 46202, США.
2
Regenstrief Institute, Inc., Центр биомедицинской информатики, 1101 W. 10th St,
Indianapolis, IN 46202, США.
3
Центр медицинской информации и
Коммуникации, Департамент по делам ветеранов, Здоровье ветеранов
Администрация, Служба исследований и разработок в области здравоохранения, 1481 W.
10th St, 11H, Индианаполис, IN 46202, США.
4
Онкологический центр Моффитта, Отдел
по результатам лечения и поведению, 4115 Ист Фаулер авеню, Тампа, Флорида 33617,
США.
5
Департамент педиатрии, Медицинский факультет Университета Индианы, 410 W
10th Street Suite 1001, Индианаполис, IN 46202, США.
6
Merck & Co., 2000
Galloping Hill Road, Кенилворт, Нью-Джерси 07033, США.
Получено: 21 декабря 2016 г. Принято: 7 августа 2017 г.
Ссылки
1.Центры по контролю и профилактике заболеваний. Генитальная инфекция ВПЧ — Информационный бюллетень CDC
. Атланта: Национальный центр по ВИЧ / СПИДу, вирусным гепатитам, венерическим заболеваниям и туберкулезу
Профилактика; Июль 2017 г. Доступно по адресу: https://www.cdc.gov/std/hpv/HPV-FS-July-
2017.pdf.
2. Национальные институты здравоохранения. ВПЧ и рак. Bethesda: Национальный институт рака
; 2015.
3. Управление по санитарному надзору за качеством пищевых продуктов и медикаментов США. FDA одобрило Гардасил 9 для профилактики
определенных видов рака, вызванных пятью дополнительными типами ВПЧ.Сильвер Спринг:
Администрация FaD; 2014.
4. Стокли С., Джейараджа Дж., Янки Д., Кано М., Джи Дж., Роарк Дж., Кертис Р., Марковиц
L, Отдел иммунизации NCfIaRD, CDC. Вирус папилломы человека
Охват вакцинацией подростков, 2007–2013 гг. , И постлицензия
, И постлицензия
, 2006–2014 гг. — США. MMWR Morb Mortal
Недельный отчет 2014; 63 (29): 620–4.
5. Рейган-Штайнер С., Янки Д., Джейараджа Дж., Элам-Эванс Л.Д., Кертис С.Р., МакНил Дж.,
Марковиц Л.Е., Синглтон Дж.Национальный, региональный, штатный и выбранный район
Охват вакцинацией подростков в возрасте 13–17 лет — США,
2015. MMWR Morb Mortal Wkly Rep. 2016; 65 (33): 850–8.
6. Гилки М.Б., Мало Т.Л., Шах, П.Д., Холл, штат Мэн, Брюэр, Н.Т. Качество информации врача
о вакцине против вируса папилломы человека: результаты национального исследования
. Биомарк эпидемиологии рака Пред. 2015 ноя; 24 (11): 1673-9.
7. Гилки М.Б., Кало В.А., Мосс Дж.Л., Шах П.Д., Марчиньяк М.В., Брюэр Н.Т.Провайдер
коммуникация и вакцинация против ВПЧ: влияние рекомендации
на качество. Вакцина. 2016; 34 (9): 1187–92.
8. Бендик М., Мэйо Р.М., Паркер В.Г. Факторы, способствующие распространению вакцины против ВПЧ
у женщин студенческого возраста. J Cancer Educ. 2009; 24: 17.
J Cancer Educ. 2009; 24: 17.
9. Центры по контролю и профилактике заболеваний. Охват вакцинацией на национальном уровне и уровне штата
среди подростков в возрасте 13–17 лет — США, 2011 г. MMWR
Morb Mortal Wkly Rep. 2012; 61 (34): 671–7.
10. Брюер Н.Т., Готтлиб С.Л., Рейтер П.Л., Макри А.Л., Лиддон Н., Марковиц Л., Смит Дж. С..
Продольные предикторы начала вакцинации против вируса папилломы человека среди
девочек-подростков в географической зоне высокого риска. Sex Transm Dis. 2011. 38 (3): 197–204.
11. Лиддон NC, Худ Дж. Э., Лейхлитер Дж. С.. Намерение получить вакцину против ВПЧ и причины
для отказа от вакцинации среди невакцинированных подростков и молодых женщин:
результаты Национального обследования роста семьи за 2006–2008 годы.Вакцина.
2012; 30 (16): 2676–82.
12. Zimet GD, Weiss TW, Rosenthal SL, Good MB, Vichnin MD. Причины вакцинации против ВПЧ, отличной от
, и планы вакцинации в будущем среди женщин в возрасте 19–26
лет. BMC Womens Health. 2010; 10 (1): 27.
BMC Womens Health. 2010; 10 (1): 27.
13. Чаудри Б., Ван Дж., Ву С., Маглионе М., Мохика В., Рот Э., Мортон СК,
Шекелль PG. Систематический обзор: влияние медицинских информационных технологий
на качество, эффективность и стоимость медицинской помощи.Ann Intern
Med. 2006. 144 (10): 742–52.
14. Гарг А.Х., Адхикари Н.К., Макдональд Х., Росас-Ареллано М.П., Деверо П.Дж.,
Бейене Дж., Сэм Дж., Хейнс РБ. Влияние компьютеризированных клинических решений
систем поддержки на работу практикующего врача и исходы для пациентов: систематический обзор
. ДЖАМА. 2005. 293 (10): 1223–38.
15. Кавамото К., Хулихан Калифорния, Балас Е.А., Лобач Д.Ф. Улучшение клинической практики
с использованием систем поддержки принятия клинических решений: систематический обзор испытаний до
для выявления характеристик, критически важных для успеха.BMJ (Clin Res Ed). 2005; 330 (7494): 765.
16. Лобач Д., Сандерс Г. Д., Брайт Т.Дж., Вонг А., Дурджати Р., Бристоу Е., Бастиан Л.,
Д., Брайт Т.Дж., Вонг А., Дурджати Р., Бристоу Е., Бастиан Л.,
Който Р., Самса Г., Хассельблад В. и др. Обеспечение медицинского обслуживания
принятие решений посредством поддержки принятия клинических решений и знаний
менеджмент. Evid Rep Technol Assess. 2012; 203: 1–784.
17. Рошанов П.С., Мисра С., Герштейн Х.С., Гарг А.Х., Себальдт Р.Дж., Маккей Дж.А., Вайсе-
Келли Л., Наварро Т., Вильчинский Н.Л., Хейнс РБ. Компьютеризированные клинические решения
Системы поддержки для ведения хронических заболеваний: лицо, принимающее решения —
Систематический обзор партнерства исследователей.Реализуйте Sci. 2011; 6: 92.
18. Сим И., Горман П., Гринес Р.А., Хейнс Р.Б., Каплан Б., Леманн Х., Тан П.С.
Системы поддержки принятия клинических решений для практики доказательной медицины
. J Am Med Inform Assoc. 2001. 8 (6): 527–34.
19. Блюменталь Д., Тавеннер М. Регламент «разумного использования» электронных медицинских карт
. N Engl J Med. 2010. 363 (6): 501–4.
N Engl J Med. 2010. 363 (6): 501–4.
20. Уровень 2. Соответствующий требованиям профессионал (EP) Значимое использование Ядро и меры меню.
[http://www.cms.gov/Regulations-and-Guidance/Legislation/
EHRIncentivePrograms / Downloads / Stage2_MeaningfulUseSpecSheet_
TableContents_EPs.pdf]. По состоянию на 30 июня 2017 г.
21. Раджамани С., Биеринджер А., Маскоплат М. Характеризация доступа к клинической поддержке принятия решений
, предлагаемой информационной системой иммунизации в Миннесоте.
Online J Public Health Informa. 2015; 7 (3): e227.
22. Biondich PG, Dixon BE, Duke J, Mamlin B, Grannis S, Takesue BY, Downs SM,
Tierney WM.Regenstrief медицинской информатики: опыт работы с системами поддержки клинических решений
. В: Гринес Р.А., редактор. Поддержка принятия клинических решений: путь к широкому внедрению
. 2-е изд. Берлингтон: Эльзевир, Инк .; 2014. с. 165–87.
23. McDonald CJ, Hui SL, Tierney WM. Влияние компьютерных напоминаний о вакцинации против гриппа
Влияние компьютерных напоминаний о вакцинации против гриппа
на заболеваемость во время эпидемий гриппа. МД
Вычисл. 1992. 9 (5): 304–12.
24. Декстер П.Р., Перкинс С., Оверхэдж Дж. М., Махарри К., Колер Р. Б., Макдональд С. Джей.Компьютеризированная система напоминаний
для увеличения использования профилактической помощи для
госпитализированных пациентов. N Engl J Med. 2001. 345 (13): 965–70.
25. Zimet G, Dixon BE, Xiao S, Tu W, Kulkarni A, Dugan T., Sheley M, Downs SM:
Напоминания и рекомендательные сценарии для врачей по вакцинации против ВПЧ: рандомизированное клиническое испытание
. Acad Pediatr. 2017. (В печати).
26. Кастинг М.Л., Уилсон С., Диксон Б.Е., Даунс С.М., Кулкарни А., Зимет Г.Д. Качественное исследование
осведомленности медицинских работников и информационных потребностей
относительно девятивалентной вакцины против ВПЧ.Вакцина. 2016; 34 (11): 1331–4.
27. Кастинг М.Л. , Уилсон С., Диксон Б.Е., Даунс С.М., Кулкарни А., Зимет Г.Д. Здравоохранение
, Уилсон С., Диксон Б.Е., Даунс С.М., Кулкарни А., Зимет Г.Д. Здравоохранение
убеждений и взглядов поставщиков в отношении компенсации риска после вакцинации против ВПЧ
. Papillomavirus Res. 2016; 2: 116–21.
Dixon et al. BMC Medical Informatics and Decision Making (2017) 17: 119 Стр. 9 из 10
Содержимое любезно предоставлено Springer Nature, применяются условия использования. Права защищены.
Стратегии интеллектуального анализа данных для повышения толерантности к мультиплексному иммуноанализу на мышиной модели инфекционных заболеваний
Реферат
Методологии мультиплексирования, особенно те, которые обеспечивают высокую пропускную способность, генерируют большие объемы данных.Накопление таких данных (например, геномики, протеомики, метаболомики и т. Д.) Быстро становится все более распространенным явлением и, следовательно, требует разработки и реализации эффективных стратегий интеллектуального анализа данных, предназначенных для биологических и клинических приложений. Мультиплексный иммуноферментный анализ (MMIA) на платформе xMAP или MagPix (Luminex), который поддается автоматизации, предлагает большое преимущество перед традиционными методами, такими как вестерн-блоттинг или ELISA, для повышения эффективности серодиагностики инфекционных заболеваний.MMIA позволяет эффективно обнаруживать антитела и / или антигены для широкого спектра инфекционных агентов одновременно в образцах крови хозяина в одном реакционном сосуде. В процессе MMIA генерирует большие объемы данных. В этом отчете мы демонстрируем применение инструментов интеллектуального анализа данных о том, как данные большого объема могут улучшить толерантность анализа (измеряемую с точки зрения чувствительности и специфичности) путем анализа экспериментальных данных, накопленных за два года. Сочетание предварительных знаний с инструментами машинного обучения обеспечивает эффективный подход к постоянному повышению диагностической мощности анализа.Кроме того, это исследование обеспечивает углубленную базу знаний для изучения патологических тенденций инфекционных агентов в колониях мышей по многомерной шкале. Методы интеллектуального анализа данных с использованием серодетектирования инфекций у мышей, разработанные в этом исследовании, могут использоваться в качестве общей модели для более сложных приложений в эпидемиологии и клинических трансляционных исследованиях.
Образец цитирования: Mani A, Ravindran R, Mannepalli S, Vang D, Luciw PA, Hogarth M, et al. (2015) Стратегии интеллектуального анализа данных для повышения толерантности к мультиплексному иммуноанализу на мышиной модели инфекционных заболеваний.PLoS ONE 10 (1): e0116262. https://doi.org/10.1371/journal.pone.0116262
Академический редактор: Ларс Кадерали, Технический университет Дрездена, медицинский факультет, ГЕРМАНИЯ
Поступила: 09.07.2014; Одобрена: 4 декабря 2014 г .; Опубликовано: 23 января 2015 г.
Авторские права: © 2015 Mani et al. Это статья в открытом доступе, распространяемая в соответствии с условиями лицензии Creative Commons Attribution License, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии указания автора и источника
Доступность данных: Все данные включены в файлы вспомогательной информации.
Финансирование: Признается частичное финансирование инициативы по протеомике и информатике Департамента патологии и лабораторной медицины в Медицинском центре Калифорнийского университета в Дэвисе. VVK и SM были частично поддержаны грантами NIH P20 MD 002732 и P20 CA 138025. Финансирующие организации не играли никакой роли в дизайне исследования, сборе и анализе данных, принятии решения о публикации или подготовке рукописи.
Конкурирующие интересы: Авторы заявили, что конкурирующих интересов не существует.
Введение
В биомедицинских исследованиях используются многие модели in vivo (например, дрожжи, черви, мухи, рыба, мышь, крыса, обезьяна и т. Д.), Однако модель мыши остается наиболее полезной, широко распространенной и важной для биомедицинские исследования и клиническая значимость [1–5]. Приблизительно 40 миллионов мышей используются в различных биомедицинских / биологических исследовательских проектах, которые проводятся во многих академических и промышленных учреждениях каждый год в США [6]. Поэтому крайне важно тщательно поддерживать качество этих исследовательских животных.В частности, необходимо тщательно контролировать инфекционные агенты, которые часто встречаются в исследовательских колониях мышей. Учитывая чрезвычайно большое количество используемых для исследования животных, крайне важно, чтобы методы обнаружения были точными, высокоэффективными (имели высокую пропускную способность) и, желательно, автоматизированными. Мы опубликовали информацию о разработке, валидации и клиническом внедрении мультиплексных иммуноанализов на микрогранулах (MMIA) для достижения вышеуказанных целей с использованием серологического рутинного скрининга колоний мышей и нечеловеческих приматов на конкретные инфекционные патогены, чтобы помочь в установлении и поддержании конкретного патогена. бесплатный (SPF) статус [7, 8].В этом отчете мы описываем использование вычислительных подходов, основанных на алгоритмах, для анализа и непрерывной интерпретации умеренно больших объемов сложных наборов данных, полученных в процессе характеристики состояния инфекционных патогенов у лабораторных мышей. Кроме того, эти исследования могут предоставить систему для обработки таких данных в биомедицинских исследованиях в целом (например, в геномике, протеомике, метаболомике и т. Д.) [9, 10].
Как описано выше, поддержание колоний мышей SPF имеет решающее значение для биомедицинских исследований.Экспериментальные животные, подвергшиеся воздействию инфекционных агентов или инфицированные ими, могут давать сомнительные данные, тем самым искажая результаты данного исследования. Из-за манипуляций с геномом лабораторных мышей основное заболевание или даже основная инфекция без признаков заболевания может изменить генотип и фенотип, что приведет к сомнительным или вводящим в заблуждение результатам [11]. Штаммы лабораторных мышей могут быть проверены на наличие нескольких важных инфекционных патогенов [12–19] в рамках рутинной практики управления колониями, чтобы поддерживать хорошо охарактеризованные и надежные экспериментальные системы [20].Следовательно, жизненно важно, чтобы колонии мышей поддерживались в среде, свободной от патогенов, что сводит к минимуму возможность вспышек заболеваний, которые могут не только уничтожить колонию, но и привести к сомнительным экспериментальным результатам [21].
Серологический надзор является важным компонентом поддержания здоровых колоний мышей. Мониторинг животных для получения точных сведений об общих патогенных микроорганизмах не только желателен для поддержания колонии, но и имеет решающее значение для сохранения особых линий мышей (например, генетически модифицированных или созданных штаммов).Сыворотку мышей-дозорных можно тестировать с помощью обычных иммуноанализов с помощью иммуноферментного анализа (ELISA) или непрямого флуоресцентного анализа антител (IFA). Критическим ограничением обычных иммуноанализов является то, что они могут обнаруживать только один инфекционный агент в каждом образце сыворотки, что приводит к неэффективной системе тестирования. Чтобы обойти это ограничение, более эффективно внедрить технологию иммуноанализа с мультиплексными микрошариками (MMIA). MMIA может измерять до 100 аналитов за одну реакцию с высокой пропускной способностью [22].Этот метод был реализован для различных биомедицинских исследований и клинических приложений (например, иммунология / трансплантация, инфекционные заболевания, рак, неврологические заболевания, детская медицина и т. Д.). За подробностями читатель может обратиться к обширным обзорным статьям в этой области [23–25]. Мы успешно внедрили MMIA для рутинного серологического надзора за колониями мышей в Лаборатории сравнительной патологии (Калифорнийский университет в Дэвисе) и в лабораториях Джексона (Бар-Харбор, Мэн, США).Использование вычислительных методов для анализа и интерпретации данных было неотъемлемой частью предыдущих исследований. В экспериментальном исследовании Хан и его сотрудники разработали протокол MMIA для серодетекции множественных инфекционных патогенов [7].
В этом исследовании мы предлагаем модели инструментов интеллектуального анализа данных для оценки больших объемов данных, полученных в системе мультиплексного иммуноанализа. Мы определили обучающий набор на основе подтвержденных экспериментальных данных (одновременное обнаружение антител к 9 различным инфекционным агентам) из 1161 образца сыворотки [7].Тестирование Данные включали более 15 000 животных, которые регулярно тестировались в двух разных животноводческих помещениях в течение двух лет. Этих мышей обследовали на наличие одного и того же набора из девяти инфекционных агентов. Кумулятивная проверка этих результатов с использованием инструментов интеллектуального анализа данных позволяет эффективно контролировать производительность теста в колониях мышей, возможный контроль качества данных, а также оценивать присущую толерантность к производительности анализа, поскольку большое количество образцов тестируется регулярно.
Перед внедрением анализа в полевых условиях его качество устанавливается в процессе производства. После завершения опросов информация о проведенных анализах редко используется для обратной связи, если только нет подозреваемой проблемы с результатами. В эпоху подходов, основанных на данных, знания — это информация, и важны как положительные, так и отрицательные отзывы о производительности. Завершенные результаты мультиплексного иммуноанализа на колониях мышей могут содержать несколько уровней ценной информации, которая может быть использована для улучшения на всех этапах конвейера: оптимизация анализа, определение порогового значения для дифференциации между истинно положительными и положительными результатами.отрицательные результаты, идентификация выбросов, влияние на различия в качестве расходных материалов, биологические изменения в колониях мышей, мутационные изменения тестируемых инфекционных агентов и другие переменные, зависимые от колоний мышей. Большой объем ранее собранных мультиплексных иммуноанализов за двухлетний период исследований предоставляет модельные данные для изучения полезности оптимизации всех аспектов производства, валидации, внедрения и развертывания анализов на основе обратной связи. Эта модель для анализа полевых данных будет постоянно повышать ценность для значительного повышения точности многих других форматов биологических и клинических анализов.
Материалы и методы
Утверждение этических норм: (1) Мышей содержали в лаборатории Джексона в утвержденных AAALAC помещениях для животных с использованием программ ухода за животными в соответствии с Руководством службы общественного здравоохранения по уходу и использованию лабораторных животных. Это исследование было рассмотрено и одобрено комитетом по уходу за животными и их использованию. Название комитета — Комитет по уходу и использованию животных в лаборатории Джексона. (2) Что касается облегчения страданий, мы получаем мышей для наблюдения за здоровьем из всех комнат для мышей.У мышей берут кровь для серологического тестирования, мышей умерщвляют путем смещения шейных позвонков. Затем мышей вскрывают и собирают образцы для диагностического тестирования .
Мультиплексный иммунный анализ на микрогранулах (MMIA)
Вирусы, очищенные градиентом плотности сахарозы, были приобретены у Advanced Biotechnologies Inc., (Колумбия, Мэриленд): вирус диареи телят Небраски (NCDV) для вируса эпизоотической диареи новорожденных мышей (EDIM), вирус энцефаломиелита мышей Тейлера / штамм GDVII (GD7 ), вирус гепатита мышей (MHV), минутный вирус мыши (MMV), вирус пневмонии (PVM), вирус Сендай и вирус осповакцины для вируса эктромелии (ECTRO).Респираторно-кишечный орфанный вирус (вирус Рео-3) и M. pulmonis (MYC) были культивированы в нашей лаборатории. Лизаты клеток готовили для покрытия микрогранул, как описано ранее [7, 8].
Все антигены были приготовлены для связывания гранул, как описано ранее [7, 8]. Оптимальную концентрацию для каждого антигена определяли путем связывания различных наборов микрошариков (2,5 × 10 6 шариков / соединение) с диапазоном концентраций белка для каждого антигена [7, 8]. Покрытые микрошарики для каждого антигена тестировали с сывороткой инфицированных мышей, чтобы выбрать концентрацию антигена, которая показывала самый сильный положительный сигнал и самый низкий фон (по сравнению с нормальной сывороткой).Оптимальные концентрации антигенов были ковалентно конъюгированы с карбоксилированными микрошариками (Luminex Corp., Остин, Техас) для крупномасштабного связывания (2,5 × 10 7 шариков / соединение) в соответствии с инструкциями производителя (http://www.luminexcorp.com/uploads/ data / Technology% 20Tips% 20FAQ / Рекомендации% 20for% 20Scaling% 20Up% 20Antibody% 20Coupling% 20Reactions% 200407% 2010242.pdf). Три набора шариков были объединены в качестве внутреннего контроля для анализа: 1) биотин-конъюгированный козий иммуноглобулин G (IgG) (Rockland Immunochemicals, Gilbertsville, PA) в концентрации 100 мкг / мл в качестве белка положительного контроля для реакции со стрептавидин-R-фикоэритрином, 2) кроличий антимышиный IgG (Bethyl Laboratories, Монтгомери, Техас) 1 мкг / мл в качестве положительного контроля для добавления образца и 3) бычий сывороточный альбумин (BSA; 100 мкг / мл) (Pierce, Rockford, IL) в качестве отрицательного контрольный белок.
Мультиплексный анализ был проведен, и данные были собраны, как описано ранее [7, 8]. Хотя в течение периода экспериментов (приблизительно два года) гранулы обычно производились из нескольких партий, подготовка антигена и связывание с гранулами выполнялись последовательным образом в соответствии со стандартными рабочими процедурами. Дополнительный контроль качества на различных этапах подготовки снижает любые другие экспериментальные различия между различными партиями и, таким образом, повышает надежность данных.
Экспериментальные данные для «Тренировочного набора»
В каждом эксперименте по мультиплексному иммуноанализу использовали два типа контрольных образцов планшета: положительный (высокий и низкий титр) и отрицательный на антитела против всех девяти патогенов. Были получены два положительных контрольных образца, один с высоким, а другой с низким титром антител, представляющих каждый патоген [8]. Для создания этих образцов положительного контроля отбирали отдельные положительные сыворотки (один высокий и один низкий титр) на каждый патоген от мышей, инфицированных каждым из патогенов.Такие индивидуально выбранные сыворотки для каждого из девяти патогенов затем смешивали в равной пропорции для получения двух отдельных пулов (один с высоким и один с низким титром) положительных контрольных сывороток. Для отрицательного контроля на планшете объединяли образцы от неинфицированных мышей, отрицательные по антителам против всех 9 патогенов с помощью ELISA. Готовили аликвоты положительных и отрицательных контрольных планшетов и хранили замороженными при -80 ° C до использования.
Воспроизводимость анализа определялась как процентное отклонение результатов мультиплексного анализа для образцов положительного контроля с данными, полученными в результате двенадцати независимых экспериментов (выполненных в CCM).Вариация от пластины к пластине оценивалась от 2 до 6% [8]. Общий процентный разброс среди других сайтов составлял от 13 до 15%, за исключением одного инфекционного агента, Mycoplasma, который составлял 20%.
Экспериментальные данные для «Test Set»
Данные рутинных полевых испытаний были получены в лаборатории Джексона (Jax) и лаборатории сравнительной патологии (CPL) Калифорнийского университета в Дэвисе в течение двух лет. Эти данные называются «Набором тестовых данных». И планшет-контроль, и «набор тестовых данных» не специфичны для конкретной линии мышей.После того, как анализ был проведен в соответствующих лабораториях, результаты периодически отправлялись обратно в CCM по электронной почте (формат MS Excel). Каждый файл был помечен датой проведения экспериментов. Все листы Excel были объединены с использованием сценариев awk, написанных собственными силами. Во время рутинных полевых испытаний анализы проводились на основе одного образца (а не в двух экземплярах). Воспроизводимость анализа на месте реализации измеряли независимо, и процентные вариации между различными наборами микробусин были одинаковыми между Jax и CPL, но выше, чем у CCM (приблизительно от 6 до 10%) [8].
Дизайн исследования для интеллектуального анализа данных
На рис. 1 показана блок-схема обзора рабочего процесса. «Набор обучающих данных» был разработан с использованием тщательно проверенных данных экспериментально инфицированных животных [7, 8]. Данные были проверены, чтобы гарантировать качество, воспроизводимость и вариабельность анализа в пределах и между установленными CV экспериментов [8]. Базовые значения реактивности каждого набора микрошариков по отношению к образцам от нормальных (здоровых / неинфицированных) мышей сначала устанавливали с точки зрения необработанной медианной интенсивности флуоресценции (MFI).Используя комбинацию многомерной статистики, которая учитывает интерференцию анализа, было определено значение отсечки для каждого набора микрошариков (см. Ниже).
Рис. 1. Блок-схема метода анализа данных серологического надзора за колониями мышей.
Результаты мультиплексного иммуноанализа на микрогранулах (MMIA), разработанные для обнаружения нескольких вирусов, оптимизируются и проверяются для разработки обучающего набора. Затем в качестве тестового набора использовались анализы, проведенные в колониях мышей, с использованием различных алгоритмов интеллектуального анализа данных.Этот процесс приводит к лучшему обнаружению, оптимизации и развертыванию серологического обнаружения инфекционных заболеваний в колониях мышей. Предлагаемый подход может быть динамически реализован для любой крупномасштабной диагностики для клинических и трансляционных исследований.
https://doi.org/10.1371/journal.pone.0116262.g001
Построение «Обучающего набора данных»
Данные ранее опубликованного валидационного исследования были использованы для создания «Обучающего набора данных».Эти данные состоят из 1632 образцов сыворотки для всех 9 патогенов, собранных в двух экземплярах. Значения MFI для микрогранул, покрытых BSA (см. Получение антигена и связывание с микрогранулой) в мультиплексных анализах, указали на неспецифическую реактивность образца [8]. Обычно значение MFI> 100 в образце для микрогранул BSA свидетельствует о неспецифической перекрестной реактивности. Такая неспецифическая перекрестная реактивность является значительным источником неправильной классификации (рис. 1 и таблица 2 Равиндрана и др. [8]). Таким образом, все образцы со значениями MFI для микрогранул BSA> 100 были удалены, в результате чего осталось 1161 образца.
Определение порогового значения анализа
сырых значений MFI из «Обучающего набора данных» использовались без дальнейших изменений. Надежная линейная регрессия была проведена на наблюдаемых квантилях в сравнении с теоретическими, чтобы определить, какое линейное преобразование статистики t даст нормальное распределение, а затем масштабировано соответствующим образом с использованием процедуры квантильной нормализации. Перед анализом данные были визуализированы с помощью диаграмм в виде ящиков и усов и диаграмм рассеяния.Измеренные уровни MFI были скорректированы до одного и того же межквартильного диапазона. Подгонка линейной модели была определена для каждого патогена с использованием пакета LIMMA в R. Для линейной модели были определены три разные группы: (a) нормальные образцы, (b) фоновые значения из одноположительных сывороток, которые были положительными для одного патогена и отрицательный для других восьми неспецифических патогенов и (c) сигналы от образцов положительного контроля. Средние значения оценивали с помощью линейного моделирования для каждой из групп (каждое измерение проводилось в двух экземплярах) в соответствии с ранее описанной процедурой [24, 26].Вкратце, изменения были рассчитаны по трем условиям (a, b и c) путем подбора линейной модели к данным, а статистическая значимость оценивалась с помощью двухэтапного процесса. Во-первых, был получен набор аналитических данных, который охватывал каждую группу, для которой значимый сигнал был обнаружен по крайней мере в одном сравнении между нормальным (или неспецифическим фоном из одной положительной сыворотки). За этим последовала дифференциальная экспрессия при множественных сравнениях, обнаруженных с помощью теста F вместе с отдельными тестами F для каждого патогена.Были оценены складчатые изменения и значения p были скорректированы с использованием процедуры Бенджамини-Хохберга (данные не показаны). Расчетные средние значения для каждой группы перечислены в таблице A в файле S1 (вспомогательная информация).
Пороговые значения были рассчитаны, как описано ранее, из двух источников фона [8]: (a) фон из нормальных образцов (Bkgrd) определяется как средний MFI каждого микробусинки по сравнению с нормальными образцами, (b) единичные положительные сыворотки положительны для антитела к одному, но отрицательны на антитела к восьми неспецифическим инфекционным агентам, вызывающим фон (средний MFI) против каждого из девяти наборов неспецифических микрогранул (SP Bkgrd).Используя фон из этих двух источников, значение отсечки (CO) для каждого набора микрогранул рассчитывается как: «Нормальный и S-P Bkgrd + (3 × SD)», где SD — стандартное отклонение соответствующих фонов. Это определение отсечения предполагает, что данные в каждой подгруппе распределены нормально. Например, для микрошарика GD7 значение отсечки MFI равно 90; реактивность любого образца против микрогранул GD7> 90 считается положительной для инфицирования GD7. Пороговое значение для каждого инфекционного агента разное и колеблется от 72 до 246 (таблица 1).
Построение «Тестового набора данных»
Экспериментальные данные из двух сайтов (Jax и CPL), где был реализован мультиплексный иммуноанализ микрогранул для рутинного тестирования мышей на инфекционные агенты, были использованы для создания «набора данных тестирования» следующим образом: CPL, Калифорнийский университет в Дэвисе (n = 3850) и Jax (n = 15350) для оценки 9 классов (чувствительность и специфичность девяти наборов микрогранул). Все MMIA были выполнены с внутренним контролем микрогранул, покрытых BSA, для определения фоновой реактивности каждого образца мыши [7].Как и в случае с дизайном «Набор обучающих данных», все образцы с уровнями BSA> 100 (MFI) были удалены, чтобы получить окончательный набор для тестирования из 15 403 образцов для всех 9 микрогранул. Сокращение данных (удаление образцов сыворотки из-за неспецифических взаимодействий или перекрестной реактивности) как в «Наборе данных для обучения», так и в «Наборе данных для тестирования» не зависит от местоположения. Примерно одинаковый процент данных был удален из обоих мест (из-за неспецифической реактивности образцов против микрогранул BSA) во время процесса фильтрации данных при построении «Обучающего набора данных» и «Тестового набора данных», 20.3% и 19,7% соответственно.
Интеллектуальный анализ данных
Было реализовано несколько классификационных схем согласно блок-схеме (рис. 1). Идентификация 9 различных инфекционных агентов была представлена их соответствующими классификационными метками, и каждая мышь была сопоставлена с их вектором атрибутов. Окончательные размеры тестовой и обучающей выборок составили 15 403 и 1 161 90 424 соответственно. («Набор данных для обучения» и «Набор данных для тестирования» включены во вспомогательные информационные таблицы B и C в файле S1).Weka версии 3.5.7 (http://www.cs.waikato.ac.nz/ml/weka/), разработанная Университетом Вайкато в Новой Зеландии, представляет собой программное обеспечение, в котором собраны различные современные методы машинного обучения. использовались алгоритмы [27–29].
Производительность «набора обучающих данных»
Качество «обучающего набора данных» оценивалось с помощью трех различных схем классификации (J48, байесовская сеть и случайный лес) с использованием Weka. Алгоритм J48, основанный на статистической системе классификации C4.5, которая, как известно, хорошо работает с выборочным распределением [30], байесовская сеть использует вероятностную оценку [31], в то время как случайный лес [32] позволяет использовать несколько моделей, популярная классификация. схема.Для каждого алгоритма обучающая выборка подвергалась перекрестной проверке с различными значениями «k» (k = 5, 10, 15 и 20), и было измерено соответствующее среднее значение истинно положительной скорости. Набор данных был случайным образом разбит на «k» разделов равного размера. Каждый раздел используется для тестирования по очереди, а остальное используется для обучения, т. Е. Каждый раз 1 / k th набора данных используется для тестирования, а остальное — для обучения, и процедура повторяется k раз, так что все данные используются для обучения и тестирования ровно один раз.Поскольку для k> 10 не было измерено значительных изменений в истинно положительной частоте, были использованы результаты десятикратной перекрестной проверки «Обучающего набора данных». Никаких дополнительных изменений в данные не производилось. Три алгоритма, используемые для проверки обучающего набора, являются частью десяти основных схем классификации, часто используемых в литературе [33], а детали реализации схем предоставлены Виттеном и др. [29].
Приложение к «Набору данных тестирования»
«Набор данных для обучения», разработанный выше, был использован для оценки производительности «Набор данных для тестирования».Мы использовали 26 различных алгоритмов (классификатор мета-класса, J48, SMO, простая логистика, многослойное восприятие, ленивый ibk, LMT, таблица решений правил, Meta Bagging Meta Logi Boost, Kstar, Rules PART, REP Tree, Meta Random Committee, Random Forest, Подпространство случайного леса, классификация с помощью регрессии, логистика, Rules One R, Rules Zero R, байеснет, случайное дерево, Naives Bayes, классификатор с метафильтрованием, обновляемый NaiveBayes и классификатор выбора атрибутов) с использованием «Обучающего набора данных» (1161 образец) на «Набор тестовых данных» (15 403 выборки).Качество «Обучающего набора данных» хорошо охарактеризовано экспериментальной проверкой [8], и поэтому было достаточно трех четко установленных схем классификации. Поскольку мы хотели создать модель, которая предсказывает лучший результат из «набора данных тестирования», мы реализовали ряд алгоритмов (всего 26, вспомогательная информация).
Показатели эффективности
Истинно-положительный результат (TP) обеспечивает меру количества положительных событий, положительных для вирусной инфекции, а истинно отрицательный (TN) обеспечивает количество отрицательных событий, правильно спрогнозированных в соответствии с данной схемой классификации.Ложноположительный результат (FP) дает оценку отрицательных событий, которые ошибочно предсказаны как положительные, в то время как ложноотрицательный (FN) оценивает количество мышей, которые были предсказаны отрицательными, но были положительными [34].
Для схем классификации с несколькими классами следует учитывать сумму по строкам (i) или столбцам (j) матрицы неточностей ( M ). Для матрицы неточностей измерения TP, TN, FP и FN для меры (класса) «n» могут быть определены следующим образом: [1]
Эти термины были объединены для определения эффективности нашего тестирования с помощью количественных категорий, таких как чувствительность (SN), специфичность (SP), положительная прогностическая ценность (PPV), отрицательная прогностическая ценность (NPV), эффективность / точность теста (TE). и коэффициент корреляции Мэтью (MCC).Эти кванторы определены следующим образом:
Чувствительность (SN) дает оценку процента реально идентифицированных положительных результатов, а специфичность (SP) дает оценку процента идентифицированных отрицательных результатов.
[2] [3]Эффективность теста оценивается на основе двух показателей, а именно: положительной прогностической ценности (PPV) и отрицательной прогностической ценности (NPV). PPV дает оценку процента положительных образцов, которые были правильно предсказаны, а NPV дает процент отрицательных образцов, которые были правильно предсказаны [35, 36].
[4] [5]Мощность предсказания модели может быть оценена либо по эффективности теста (TE), либо по коэффициенту корреляции Мэтью (MCC) [37]. Эффективность теста также обозначается как , точность теста . MCC — это, по сути, коэффициент корреляции между наблюдаемой и прогнозируемой классификациями; он возвращает значение от −100% до + 100%. Коэффициент + 100% представляет собой идеальное предсказание, 0% не лучше, чем случайное предсказание, а -100% указывает на полное несоответствие между предсказанием и наблюдением [38].TE и MCC определены следующим образом.
[6] [7]Допуск анализа и влияние отклонения отсечки
Как упоминалось выше (Таблица 1), экспериментально подтвержденные значения анализа [8] были использованы для определения различных подклассов (удельная реактивность каждого образца против девяти микрогранул, представляющих девять патогенов) в «Наборе данных тестирования». Чтобы определить толерантность (чувствительность и специфичность) нашего анализа, мы систематически и постепенно уменьшали пороговые значения.Значения отсечки были разделены на категории с шагом 5%, 15%, 25%, 40%, 55%, 75% и 90% экспериментальных значений (представленных 0%). Определения классов были переоценены в каждом случае, и «новый» «Набор тестовых данных» был переопределен для оценки. Три лучших исполнителя из 26 схем классификации, применявшихся ранее (см. Выше) (Meta Class Classifier, J48 и Simple Logic), использовались для оценки производительности всякий раз, когда набор тестов переопределяется с изменяющимся значением отсечки. Помимо использования Weka для классификации, остальная часть анализа данных была выполнена с использованием комбинации макросов Excel, сценариев awk и Perl или статистической среды R [39].
Результаты
Качество обучающего набора данных
В этом исследовании использовались два ключевых набора данных. Один набор данных был получен с использованием групп экспериментально инфицированных животных, положительных по антителам против одного инфекционного патогена в каждой группе [7, 8]. Этот набор данных был назван «Набор данных для обучения». Распределение этого набора данных показано на рисунке 2. Значения MFI для обнаружения антител против каждого инфекционного агента (включая отрицательные контроли) были нанесены на график. Эти значения MFI находятся в диапазоне от 0–500 (единицы MFI) для MMV до 0–15 000 (единицы MFI) для SEN.Таким образом, набор обучающих данных отображал большой динамический диапазон. Матрица неточностей, полученная из вышеуказанного обучающего набора, была классифицирована с использованием алгоритма J48 (10-кратная перекрестная проверка), как показано на рис. 3. Перекрестная проверка моделей имеет решающее значение для оценки того, насколько хорошо подгруппы могут рассматриваться независимо в рамках статистического анализа. . Это отражает точность прогнозной модели на практике и предоставляет значимый инструмент оценки. Матрица путаницы правильно спроецировала 97% классификационных образцов от животных с антителами против различных патогенов (отрицательные образцы были правильно предсказаны в 302 из 305 образцов).Показатели эффективности «набора обучающих данных» были спрогнозированы с использованием алгоритма J48, как указано в таблице 2. Коэффициент корреляции Мэтью (MCC) для каждой функции был выше 77% (кроме MMV) и дает нам необходимую уверенность в использовании этого « Набор обучающих данных ». Показатели эффективности были аналогичными для двух других схем классификации, байесовской сети и случайного леса (вспомогательная информационная таблица D в файле S1).
Рис. 2. Распределение средней интенсивности флуоресценции (MFI) в обучающих данных для всех девяти вирусов.
Каждая панель идентифицирует одновременное обнаружение всех девяти вирусов с наивысшим значением, представляющим мышей, которые являются положительными для определенного вируса, который идентифицирован вверху. Сокращения вирусов следующие: вирус эпизоотической диареи новорожденных мышей (EDIM), вирус энцефаломиелита мышей Тейлера / штамм GDVII (GD7), вирус гепатита мышей (MHV), минутный вирус мыши (MMV), Mycoplasma pulmonis (MYC), Пневмовирус мыши (PVM), респираторно-кишечный орфанный вирус (вирус Рео-3) (REO), вирус Сендай (SEN) и вирус эктромелии (ECTRO).
https://doi.org/10.1371/journal.pone.0116262.g002
Рис. 3. Матрица неточностей (CM) набора обучающих данных.
Экспериментально подтвержденные результаты анализа были сначала удалены на предмет несоответствий с помощью трех различных стандартных алгоритмов классификации (здесь представлены результаты из J48). Числа на диагонали определяют количество мышей, правильно идентифицированных (истинно положительных) алгоритмом, при этом верхние и нижние диагональные числа являются соответствующими ложноположительными и ложноотрицательными вхождениями, соответственно.Из 305 полных образцов, идентифицированных как отрицательные на какой-либо вирус (NEG), три мыши показали ложноотрицательные результаты (одна MMV и две SEN). Сокращения вирусов следующие: вирус эпизоотической диареи новорожденных мышей (EDIM), вирус энцефаломиелита мышей Тейлера / штамм GDVII (GD7), вирус гепатита мышей (MHV), минутный вирус мыши (MMV), Mycoplasma pulmonis (MYC), Пневмовирус мыши (PVM), респираторно-кишечный сиротский вирус (вирус Reo-3) (REO), вирус Сендай (SEN), вирус эктромелии (ECTRO) с NEG означает мышей, которые не переносят любую инфекцию этими вирусами.
https://doi.org/10.1371/journal.pone.0116262.g003
Прогностические значения различных алгоритмов классификации
Прогнозирование эффективности анализа с использованием обучающего набора на тестовом наборе чувствительно к выбору классификатора (алгоритма) для данного распределения данных. Поэтому важно оценивать результаты прогнозирования с использованием множества алгоритмов [40]. В нашем анализе использовалось несколько алгоритмов прогнозирования и отображалась взаимосвязь распределения данных в матрице неточностей, чтобы определить параметры, зависящие от порога, для различных классификаторов.Двадцать шесть алгоритмов были использованы в этом исследовании из-за их прогностической ценности, чтобы лучше понять производительность «набора тестовых данных» (положительные результаты, определяемые экспериментальными значениями отсечения), измеренные с точки зрения эффективности тестирования (TE) и коэффициента корреляции Мэтью (MCC) по сравнению с «Набор обучающих данных». Результаты трех лучших алгоритмов представлены в таблице 3. (Прогностические меры по всем алгоритмам приведены в таблице E в файле S1). Значения TE отрицательных выборок для «Обучающего набора данных» использовались для определения наиболее эффективных алгоритмов: классифицированный по мета-классу, J48 и Simple Logic обеспечивают значения TE равные 90.8%, 88,4% и 85,7% соответственно (таблица 3). В целом для «набора тестовых данных» эти алгоритмы предсказывали высокие баллы TE для большинства инфекционных агентов. Классификатор мета-класса предсказал более высокий MCC (59,2%) для отрицательных образцов (таблица 3). В отличие от эффективности тестирования и MCC, можно назначить приоритет по важности алгоритмов с мета-классификатором вверху, за которым следуют J48 и Simple Logic, относящиеся ко всем девяти инфекционным агентам, а также к отрицательным образцам.Другие показатели эффективности (чувствительность, специфичность, PPV и NPV) также следуют той же тенденции, что и TE. Значение чувствительности и специфичности через MCC для классификатора метакласса высокое (TE> 86%), что показывает его точность в прогнозировании взаимосвязи между переменными (таблицы 2 и 3).
Предел толерантности для обнаружения антител против каждого инфекционного агента в мультиплексном анализе
В рамках упомянутых выше классификаторов нам удалось охарактеризовать ~ 85% данных с надежной эффективностью тестирования (Таблица 3).В мультиплексном формате чувствительность анализа для обнаружения антител против конкретного патогена зависит от качества и производительности анализа для обнаружения других патогенов, где взаимодействия между различными наборами микрогранул, а также антител в образце могут повлиять на точность. обнаружения некоторых или всех инфекционных агентов. Пороговые значения для всех наборов микрошариков в мультиплексном анализе были определены для каждого патогена (таблица 1) [8]. Мы использовали инструменты интеллектуального анализа данных для оценки толерантности всего анализа, так как он учитывает индивидуальную чувствительность каждого микробуса, его взаимодействия с другими микрогранулами в мультиплексном анализе, а также с образцом, а также учитывает фоновые вариации анализа.Чтобы проверить предел допуска к точности каждого набора микрошариков, мы систематически изменяли пороговые значения каждого микробусин и оценивали общую производительность (рис. 4 и 5). Это было сделано путем уменьшения порогового значения для каждого класса на заранее определенный процент (материалы и методы). Например, в случае EDIM определенное значение отсечки было 141; мы уменьшили это значение на 5%, что дало нам 134. С уменьшенным порогом MCC был рассчитан для трех алгоритмов.
Рисунок 4.Показатели толерантности анализа с точки зрения эффективности теста: изменение эффективности теста (%) нанесено на график как функция уменьшения экспериментального порогового значения, которое используется для определения мышей, положительных для каждого вируса (отмеченного) в каждой панели.
Вариация рассчитывается для трех наиболее эффективных алгоритмов: классификатора мета-класса (черные символы / линии), J48 (красные символы / линии) и простой логики (зеленые символы / линии). Экспериментальное значение отсечки нанесено на 0%. Значения 50% по осям X и Y отмечены вертикальными пунктирными линиями.Сокращения вирусов следующие: вирус эпизоотической диареи новорожденных мышей (EDIM), вирус энцефаломиелита мышей Тейлера / штамм GDVII (GD7), вирус гепатита мышей (MHV), минутный вирус мыши (MMV), Mycoplasma pulmonis (MYC), Пневмовирус мыши (PVM), респираторно-кишечный орфанный вирус (вирус Рео-3) (REO), вирус Сендай (SEN) и вирус эктромелии (ECTRO).
https://doi.org/10.1371/journal.pone.0116262.g004
Рис. 5. Показатели толерантности анализа с точки зрения коэффициента корреляции Мэтью (MCC): изменение MCC (%) нанесено на график как функция уменьшения в экспериментальном отсечении, которое используется для определения мышей, положительных для каждого вируса (отмечены) на каждой панели.
Вариация рассчитывается для трех наиболее эффективных алгоритмов: классификатора мета-класса (черные символы / линии), J48 (красные символы / линии) и простой логики (зеленые символы / линии). Экспериментальное значение отсечки нанесено на 0%. Значения 50% по оси X и 0% по оси Y отмечены вертикальными пунктирными линиями. Сокращения вирусов следующие: вирус эпизоотической диареи новорожденных мышей (EDIM), вирус энцефаломиелита мышей Тейлера / штамм GDVII (GD7), вирус гепатита мышей (MHV), минутный вирус мыши (MMV), Mycoplasma pulmonis (MYC), Пневмовирус мыши (PVM), респираторно-кишечный орфанный вирус (вирус Рео-3) (REO), вирус Сендай (SEN) и вирус эктромелии (ECTRO).
https://doi.org/10.1371/journal.pone.0116262.g005
За счет уменьшения пороговых значений обнаружения для каждого патогена точность была снижена на основе индивидуальных классификаторов, изменяющих относительную скорость уменьшения для каждого набора гранул (рис. 4 и 5). Кроме того, при использовании одного и того же «набора обучающих данных» и «набора тестовых данных» с разными классификаторами было замечено, что профиль прогнозирования варьируется от одного классификатора к другому (рис. 4 и 5). В случае EDIM, ECTRO, NEG, MHV, PVM и MYC было отмечено, что производительность всех трех алгоритмов последовательно снижалась (снижение производительности на 75%).При изучении GD7 производительность классификатора метакласса и Simple Logic снижается после 75% снижения даже при увеличении производительности J48. Это могло быть результатом шума в наборе данных. В случае REO производительность Simple Logic была другой, по сравнению с двумя другими алгоритмами, на 55%. Один из таких примеров можно увидеть в случае SEN, где было замечено, что производительность классификаторов снизилась после 55%, исходя из значения отсечения. Причина непоследовательной работы некоторых алгоритмов на определенных этапах связана с наличием точек / данных (шума) в наборе данных, которые не могут быть классифицированы выбранным алгоритмом.
Обсуждение
Методы интеллектуального анализа данных предоставляют действенные и действенные инструменты для наблюдения и обеспечения достоверности для сравнения больших объемов данных, позволяя выявлять важные закономерности и корреляции. Возможности распознавания образов (интеллектуального анализа данных) в значительной степени зависят от качества обучающего набора данных [27, 29, 33, 41, 42]. В этом исследовании «Набор обучающих данных» был определен путем оптимизации экспериментального анализа [7, 8]. Чтобы проверить классификационную способность «обучающего набора данных», мы использовали три наиболее часто используемые схемы классификации (J48, сеть Байеса и случайный лес) с 10-кратной перекрестной проверкой (рис.2, 3 и таблица 2). Эти обучающие данные (1,161 × 9 инфекционных агентов + нормальные) затем используются в поле «Набор тестовых данных» (Таблица 3). Мы оценили производительность 26 различных алгоритмов с точки зрения показателей производительности (и вспомогательной информации в таблице E в файле S1). Что еще более важно, мы систематически меняли пороговое значение анализа (полученное из обучающей выборки), чтобы проверить переносимость полевых тестовых данных (рис. 4 и 5).
Согласно Файяду и др., Некоторые из общих критических факторов в протоколах интеллектуального анализа данных включают: выбор, предварительную обработку, интеллектуальный анализ данных и интерпретацию [43].Эти шаги необходимы для сокращения больших и сложных наборов данных с целью выявления и количественной оценки закономерностей для исследовательского анализа. Целью нашего исследования было расшифровать и разработать модель для одновременного обнаружения различных патогенов в популяциях мышей с помощью мультиплексного иммуноанализа. На начальных этапах сбора данных была проведена серия сокращений путем удаления выбросов и отсутствующих точек данных. Как следствие измерения всех антител в одном сосуде (мультиплексирование), перекрытие между разными группами в данных становится неизбежным, в частности, из-за отсутствия специфичности во взаимодействиях антитело-антиген в формате иммуноанализа.Другими словами, объект в классе имеет те же свойства, что и в других классах [44–46]. Даже когда характеристики хорошо выбраны и данные имеют хорошее качество (хорошо отобранные данные с меньшим шумом), результаты классификации часто будут варьироваться в зависимости от выбора различных алгоритмов и соответствующих параметров [44–46]. Несмотря на давнюю традицию исследований интеллектуального анализа данных, нет четких рекомендаций по выбору классификаторов, и каждый сталкивается с необходимостью выбора метода, который лучше всего подходит для данной задачи.
Особый интерес представляет комплексное исследование, представляющее 10 лучших алгоритмов интеллектуального анализа данных, определенных Международной конференцией IEEE по интеллектуальному анализу данных Ву и др. [33, 47]. Один из трех наших лучших исполнителей в этом исследовании (J48), который был основан на схеме C.4.5 (генерирует классификаторы, выраженные в виде деревьев решений) [30], является лучшим исполнителем, указанным в приведенной выше ссылке. Многие сравнительные исследования, подобные настоящему, относятся к конкретной проблеме или задаче. Возможно, это следствие «теоремы о запрете бесплатного обеда», которая утверждает, что без каких-либо предварительных знаний ни один метод не может быть предпочтительным [48–51].Соответствующий выбор параметров требует определенных знаний о механизмах, лежащих в основе как биологической природы анализа, так и того, как алгоритмы обрабатывают данные с настройками конфигурации по умолчанию для каждого алгоритма. В недавнем сравнении контролируемых классификаторов с использованием искусственной базы данных Амансио и др. [48] отметили, что параметры Weka по умолчанию обеспечивают надежные и согласованные результаты. Внедряя программное обеспечение Weka, мы оценили производительность нескольких классификаторов с использованием параметров по умолчанию, чтобы определить возможность повышения общей толерантности к анализу мультиплексированных и многомерных данных.Следует подчеркнуть, что выбор классификатора специфичен для текущих данных и не может считаться универсальным.
Мы получили «Набор тестовых данных» в результате рутинного тестирования девяти инфекционных агентов в течение двух лет с использованием множественной серодетекции патогенов в нескольких колониях мышей. «Набор данных для обучения» был получен от экспериментально инокулированных групп мышей; один инфекционный агент на группу. Создав «Набор тестовых данных» и «Набор данных для обучения», мы смогли оптимизировать функциональность Weka с помощью обучения механической обработке, чтобы лучше классифицировать наши данные путем анализа данных, которые позволяют нам количественно оценить нашу производительность, которая была оценена на тестовом наборе. .Этот процесс выполнялся несколькими способами и был схематично протестирован с помощью функции интеллектуального анализа данных Weka.
Традиционный статистический подход очень важен при анализе экспериментальных данных во время валидации анализа, чтобы установить базовый уровень для пороговых значений, чтобы различать истинно положительные и ложно отрицательные результаты. Тем не менее, было бы трудно предсказать какие-либо зависящие от реализации вариации, которые могут повлиять на эффективность анализа в течение более длительного периода времени, поскольку анализ выполняется несколько раз с оборотом новой партии.Несколько причин способствуют любым возможным вариациям, как при производстве анализов, так и при их реализации: Варианты производства включают качество материалов, используемых в реакциях, полученные антитела и технические вариации, тогда как в конце реализации вариации могут быть результатом эволюционных изменений последовательности вирусов и их взаимодействия с мышами, а также технических вариаций, таких как повседневная логистика различных сотрудников, выполняющих тесты. Внедрение процедуры систематической обратной связи с данными, помимо повышения переносимости результатов анализа, как показано здесь, представляет собой ценные инструменты, которые можно регулярно применять в любых условиях биологического или клинического анализа.Этот подход также позволяет выявить другие проблемы контроля качества на производственной стороне, чтобы выявить тенденции к увеличению или уменьшению конкретных инфекций в популяции мышей с помощью дизайна реализации.
Это исследование демонстрирует, что большие объемы мультиплексных данных могут быть эффективно и эффективно добыты с помощью методов добычи. Этот подход может также улучшить понимание обнаружения заболеваний за счет выявления паттернов биомаркеров крови, которые в противном случае не видны из-за огромных объемов больших объемов данных.Наша цель состояла в том, чтобы использовать подход интеллектуального анализа данных для преобразования информации в знания. Соответственно, информация, полученная в результате множественных иммуноанализов, используется для разработки модели прогнозирования для повышения точности серодетекции патогенов в популяциях лабораторных мышей. Протокол прогнозирования многообещающий, но объем включенной информации может быть недостаточным для полного использования стратегии прогнозирования. Наши результаты показали, что вычислительные методы могут быть оптимально использованы для обнаружения патогенов с высоким уровнем точности.В наших исследованиях точность и надежность шаблонов классификации, которые алгоритмы Weka обеспечивали, значительно улучшили и добавили ценность предыдущему стандартному экспериментальному тестированию [8]. Было обнаружено, что предсказатель работает надлежащим образом при применении к набору тестов, который следует тому же предполагаемому распределению набора обучения. Если внести изменение в расположение классов в тестовом наборе, производительность модели снизится [52]. Это часто приводит к медленному обучению и трудностям в интерпретации данных.Недостатки можно преодолеть, если своевременно обновлять инструменты за счет реализации более продвинутых функций. Преимущество этого недорогого подхода состоит в том, что он содержит ряд функций, которые могут помочь в построении аналитических моделей [53].
В заключение, это исследование показало полезность вычислительных инструментов для управления данными, классификации данных и оценки данных для понимания мультиплексных иммуноанализов на промежуточных этапах, что позволило улучшить анализ.По мере увеличения размера данных эти методы помогли улучшить прогнозные модели. Модель можно улучшить, используя больше информации и векторов классификации, предлагаемых методами интеллектуального анализа данных. Хотя мы сосредоточились на множественном обнаружении инфекционных агентов у мышей, инструменты и методы, разработанные в нашем проекте, имеют значение для реализации вычислительного анализа больших объемов данных, полученных в клинических трансляционных исследованиях, включая протеомику, метаболомику или функциональную геномику.
Вспомогательная информация
Файл S1. Содержит таблицы A-E.
Таблица A. Набор обучающих данных: Средние значения MFI, рассчитанные с использованием многомерной статистики. Таблица B. Набор обучающих данных: экспериментально оптимизированный набор данных тестирования для 10 атрибутов (девять инфекционных агентов и нормальный). Таблица C. Набор данных тестирования: серо-обнаружение инфекционных агентов на основе данных, развернутых в двух разных помещениях для животных. Таблица D. Матрицы неточностей обучающего набора для алгоритмов байеснета и случайного леса. Таблица E. (a) Производительность набора для тестирования с различными алгоритмами классификации — Эффективность тестирования и (b) Производительность набора для тестирования с различными алгоритмами классификации — Коэффициент корреляции Мэтью (MCC).
https://doi.org/10.1371/journal.pone.0116262.s001
(PDF)
Вклад авторов
Эксперимент задумал и спроектировал: ВВК. Проведены эксперименты: Р. Р. ДВ. Проанализированы данные: AM SM VVK. Предоставленные реагенты / материалы / инструменты анализа: PAL IHK VVK.Написал статью: AM SM RR IHK VVK. Организаторы исследования: PAL MH.
Ссылки
- 1. Адамс Дж. М., Харрис А. В., Пинкерт К. А., Коркоран Л. М., Александр В. С. и др. (1985) Онкоген c-myc, управляемый усилителями иммуноглобулина, индуцирует лимфоидную злокачественность у трансгенных мышей. Природа 318: 533–538. pmid: 3
- 0
- 2. Cheon DJ, Orsulic S (2011) Мышиные модели рака. Анну Рев Патол 6: 95–119. pmid: 20936938
- 3. Hanahan D (1985) Наследственное образование опухолей бета-клеток поджелудочной железы у трансгенных мышей, экспрессирующих онкогены рекомбинантного инсулина / обезьяньего вируса 40.Природа 315: 115–122. pmid: 2986015
- 4. Couzin-Frankel J (2014) Самый маленький пациент. Наука 346: 24–27. pmid: 25278593
- 5. Кузен-Франкель Дж. (2014) Надежда в мышке. Наука 346: 28–29. pmid: 25278594
- 6. Годовой отчет Министерства сельского хозяйства США AaPHIS (2011) Использование животных по финансовым годам. Служба инспекции здоровья животных и растений Министерства сельского хозяйства США.
- 7. Хан И.Х., Кендалл Л.В., Зиман М., Вонг С., Мендоза С. и др.(2005) Одновременное серодетектирование 10 широко распространенных инфекционных патогенов мышей за одну реакцию с помощью мультиплексного анализа. Клиническая и вакцинная иммунология 12: 513.
- 8. Равиндран Р., Хан И.Х., Кришнан В.В., Зиман М., Кендалл Л.В. и др. (2010) Валидация мультиплексного иммуноанализа на микробусинах для одновременного серодетекции нескольких инфекционных агентов у лабораторных мышей. J Immunol Methods 363: 51–59. pmid: 20965193
- 9. Маркс V (2013) Биология: большие проблемы больших данных.Природа 498: 255–260. pmid: 23765498
- 10. Лю LY, Ян Т., Джи Дж, Вэнь Кью, Морган А.А. и др. (2013) Объединение нескольких анализов «омиков» позволяет выявить серологические белковые биомаркеры преэклампсии. BMC Med 11: 236. pmid: 24195779
- 11. Фостер Х.Л. (1981) Мышь в биомедицинских исследованиях: история, генетика и дикие мыши: Academic Pr.
- 12. Андерсон К.А., Мерфи Дж. К., Фокс Дж. Г. (1986) Наблюдение за мышами на наличие антител к мышиному цитомегаловирусу.J Clin Microbiol 23: 1152–1154. pmid: 3011855
- 13. Compton SR, Homberger FR, Paturzo FX, Clark JM (2004) Эффективность трех методов микробиологического мониторинга в вентилируемых клетках. Comp Med 54: 382–392. pmid: 15357318
- 14. Iwarsson K (1990) Лабораторный мониторинг здоровья животных: вводный обзор университетских племенных колоний мышей в Стокгольме. Acta Physiol Scand Suppl 592: 139–140. pmid: 2267938
- 15. Jacoby RO, Lindsey JR (1997) Медицинское обслуживание исследовательских животных необходимо и доступно.FASEB J 11: 609–614. pmid: 9240962
- 16. Ливингстон Р.С., Бессельсен Д.Г., Штеффен Е.К., Беш-Уиллифорд С.Л., Франклин С.Л. и др. (2002) Серодиагностика мышей минутного вируса и мышиного парвовируса инфекций у мышей с помощью иммуноферментного анализа с использованием рекомбинантных белков VP2, экспрессируемых бакуловирусом. Clin Diagn Lab Immunol 9: 1025–1031. pmid: 12204954
- 17. Lussier G, Descoteaux JP (1986) Распространенность естественных вирусных инфекций у лабораторных мышей и крыс, используемых в Канаде.Lab Anim Sci 36: 145–148. pmid: 3084866
- 18. Pullium JK, Benjamin KA, Huerkamp MJ (2004) Очевидный источник мышиного парвовируса у сторожевых мышей у поставщика грызунов. Contemp Top Lab Anim Sci 43: 8–11. pmid: 15264762
- 19. Судзуки Э., Мацубара Дж., Сайто М., Муто Т., Накагава М. и др. (1982) Серологическое исследование лабораторных грызунов на предмет заражения вирусом Сендай, вирусом гепатита мышей, реовирусом типа 3 и аденовирусом мышей. Jpn J Med Sci Biol 35: 249–254. pmid: 6298492
- 20.Fox RR, Witham BA, Neleski LA, Laboratory J (1997) Справочник по генетически стандартизованным мышам JAX: Лаборатория Джексона.
- 21. Jerolmack C (2005) Том III, выпуск 1 – апрель 2007 г. Качественная социология.
- 22. Carson RT, Vignali DA (1999) Одновременное количественное определение 15 цитокинов с использованием мультиплексного проточного цитометрического анализа. J Immunol Methods 227: 41–52. pmid: 10485253
- 23. Vignali DA (2000) Мультиплексные проточные цитометрические анализы на основе частиц.J Immunol Methods 243: 243–255. pmid: 10986418
- 24. Хан И.Х., Кришнан В.В., Зиман М., Джанатпур К., Вун Т. и др. (2009) Сравнение наборов больших панелей с множеством подвесных массивов для профилирования цитокинов и хемокинов у пациентов с ревматоидным артритом. Цитометрия B Clin Cytom 76: 159–168. pmid: 18823005
- 25. Кришхан В.В., Хан И.Х., Люцив П.А. (2009) Мультиплексные иммуноанализы микрогранул с помощью проточной цитометрии для молекулярного профилирования: основные концепции и приложения протеомики.Crit Rev Biotechnol 29: 29–43. pmid: 19514901
- 26. Кришнан В.В., Равиндран Р., Вун Т., Люцив П.А., Хан И.Х. и др. (2014) Мультиплексные измерения уровней иммуномодуляторов в периферической крови здоровых субъектов: влияние аналитических переменных на основе антикоагулянтов, возраста и пола. Цитометрия B Clin Cytom.
- 27. Франк Э., Холл М., Тригг Л., Холмс Г., Виттен И.Х. (2004) Интеллектуальный анализ данных в биоинформатике с использованием Weka. Биоинформатика 20: 2479–2481. pmid: 15073010
- 28.Холл М., Фрэнк Э., Холмс Г., Пфарингер Б., Ройтеманн П. и др. (2009) Программное обеспечение интеллектуального анализа данных WEKA: обновление ;. SIGKDD Исследования. С. 10–18.
- 29. Виттен И.Х., Франк Э., Холл М.А. (2011) Интеллектуальный анализ данных: практические инструменты и методы машинного обучения. Берлингтон, Массачусетс: Морган Кауфманн. XXXIII, 629 с. п.
- 30. Куинлан-младший (1993) C4. 5: программы для машинного обучения: Морган Кауфманн.
- 31. Брейман Л. (2001) Случайный лес.Машинное обучение 45: 5–32.
- 32. Поропудас Дж., Виртанен К. (2007) Анализ результатов моделирования воздушного боя с помощью динамических байесовских сетей: IEEE Press. 1370–1377 с.
- 33. Wu X, Kumar V (2009) Десять лучших алгоритмов интеллектуального анализа данных. Бока-Ратон: CRC Press. xiii, 215 с. п.
- 34. Carugo O (2007) Подробная оценка надежности прогнозов биоинформатики с помощью графиков производительности фрагментированного прогнозирования. BMC биоинформатика 8: 380.pmid: 17931407
- 35. Gunnarsson RK, Lanke J (2002) Прогностическая ценность микробиологических диагностических тестов при наличии бессимптомных носителей. Статистика в медицине 21: 1773–1785. pmid: 12111911
- 36. Альтман Д.Г., Бланд Дж. М. (1994) Диагностические тесты. 1: Чувствительность и специфичность. BMJ: Британский медицинский журнал 308: 1552. pmid: 8019315
- 37. Мэтьюз Б.В. (1975) Сравнение предсказанной и наблюдаемой вторичной структуры лизоцима фага Т4.Biochim Biophys Acta 405: 442–451. pmid: 1180967
- 38. Hu J, Yan C (2008) Идентификация вредных несинонимичных одиночных нуклеотидных полиморфизмов с использованием информации, полученной из последовательностей. BMC биоинформатика 9: 297. pmid: 18588693
- 39. R-Core-Team (2013) R: Язык и среда для статистических вычислений. Вена, Австрия: Фонд статистических вычислений.
- 40. Сельварадж С., Натараджан Дж. (2011) Инструменты анализа данных микрочипов и добычи полезных ископаемых.Биоинформация 6: 95. pmid: 21584183
- 41. Кумар П., Радха Кришна П., Раджу С.Б. (2012) Обнаружение закономерностей с использованием интеллектуального анализа данных последовательности: приложения и исследования. Херши, Пенсильвания: Справочник по информационным наукам. х, 272 с. п.
- 42. Виттен И.Х., Франк Э. (2000) Интеллектуальный анализ данных: практические инструменты и методы машинного обучения с реализациями Java. Сан-Франциско, Калифорния: Морган Кауфманн. xxv, 371 с. п.
- 43. Файяд У, Пятецкий-Шапиро Г., Смит П. (1996) Процесс KDD для извлечения полезных знаний из объемов данных.Сообщения ACM 39: 27–34.
- 44. Епископ CM (2006) Распознавание образов и машинное обучение. Нью-Йорк: Спрингер. хх, 738 с. п.
- 45. Дуда Р.О., Харт П.Е., Сторк Д.Г. (2001) Классификация образцов. Нью-Йорк: Вили. хх, 654 с. п.
- 46. Мерфи КП (2012) Машинное обучение: вероятностная перспектива. Кембридж, Массачусетс: MIT Press. XXIX, 1067 с. п.
- 47. Wu X, Kumar V, Ross Quinlan J, Ghosh J, Yang Q и др.(2008) 10 лучших алгоритмов интеллектуального анализа данных. Знания и информационные системы 14: 1–37.
- 48. Амансио Д.Р., Комин С.Х., Казанова Д., Травьезо Г., Бруно О.М. и др. (2014) Систематическое сравнение контролируемых классификаторов. PLoS One 9: e94137. pmid: 24763312
- 49. Wolpert DH, Macready WG (1997) Нет теорем о бесплатном обеде для оптимизации. Эволюционные вычисления, транзакции IEEE на 1: 67–82.
- 50. Wolpert DH, Macready WG (2005) Коэволюционные бесплатные обеды.Эволюционные вычисления, транзакции IEEE на 9: 721–735.
- 51. Wolpert DH, Wolf DR (1996) Оценка функций вероятностных распределений из конечного набора выборок. Phys Rev E Stat Phys Plasmas Fluids Relat Interdiscip Topics 54: 6973. pmid: 9965935
- 52. Дэвис М.Н., Секер А., Фрейтас А.А., Мендао М., Тиммис Дж. И др. (2007) Об иерархической классификации рецепторов, связанных с G-белком. Биоинформатика 23: 3113. pmid: 17956878
- 53.Ducatelle F (2006) Программное обеспечение для курса интеллектуального анализа данных. Школа информатики Эдинбургского университета, Эдинбург. Доступно: www.inf.ed.ac.uk/teaching/courses/dme/html/software2.html. По состоянию на 25 декабря 2014 г.